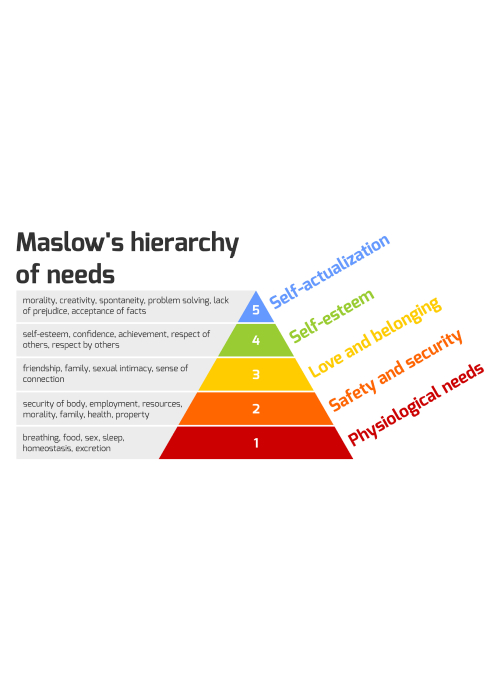
LC-FAOD Odyssey: A Preliminary Analysis, presented at INFORM 2021
Data from real-world medical records:
(from 13 patients with LC-FAOD)

38% Female

15 providers / patient

7.5 years of data / patient
Data from patient-reported outcome (PRO) survey
(from 13 patients with LC-FAOD)